Binding and Distribution¶
This page will describe how binding and distribution of tasks works on the cluster. The procedure is almost identical to LUMI, except for the GPU sections and the corresponding LUMI can be found here. Parts in quotation marks will be referenced from there.
Note
The information and options provided here apply only for jobs that are using whole nodes. This means jobs that allocate all the resources on a node, which can be achieved with the --exclusive flag.
Architecture¶
Hardware¶
This section will apply to Artemis nodes, which have two AMD EPYC 7763 sockets each, and Ares nodes, which have two AMD EPYC 7702 each. These two nodes, while they have their differences, can be treated as the same in this regard. Looking more closely at these sockets, we can see that they are all made of 64 physical cores each (SMT enables splitting a physical core into 2 logical cores), making up 128 (256 with SMT) cores per node. Looking a bit further, you will find that these 64 cores in a socket are also divided into what we call CCDs - Core Complex Dies. A CCD hold 8 cores, so a socket holds 8 CCDs. CCDs hold for example cache that the cores have access to.
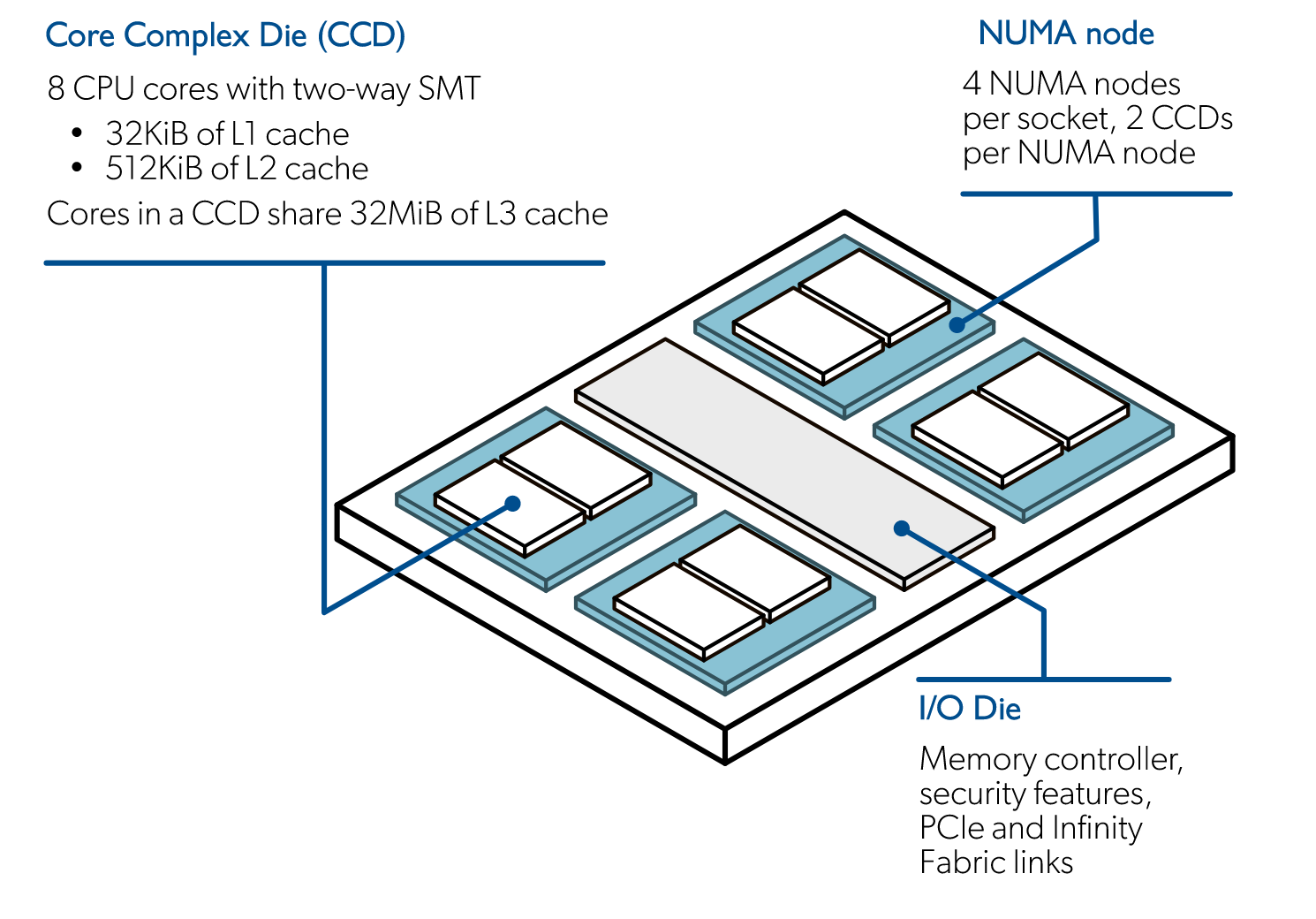 https://docs.lumi-supercomputer.eu/hardware/lumic/
https://docs.lumi-supercomputer.eu/hardware/lumic/
NUMA domains¶
Now on the image you also see another distinction, which is a NUMA node. NUMA stands for Non-Uniform Memory Access, which is a separate topic that will not be explained in depth here, but essentially it means that cores access different sections of memory at different speeds. So memory is split up into sections, a section is assigned to a NUMA domain and cores in that NUMA domain access the memory assigned to that domain faster. Cores can still access memory outside of their domains, but the access speed will be slower. See the image below.
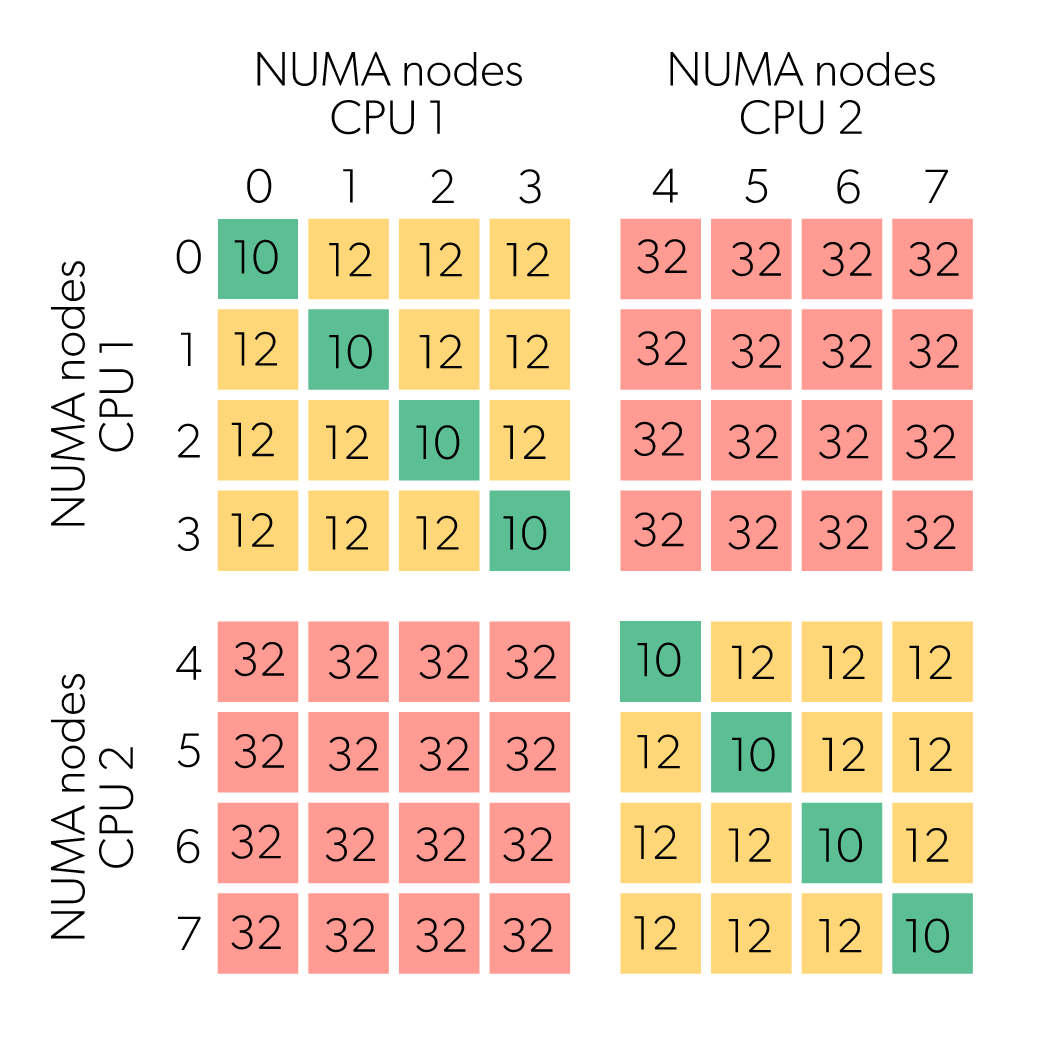 https://docs.lumi-supercomputer.eu/hardware/lumic/
https://docs.lumi-supercomputer.eu/hardware/lumic/
The image above says that accessing, for example, memory local to core 1 (NUMA domain 0), from core 0 (NUMA domain 0) would have a distance of 10. However, accessing memory of the other socket, say memory local to core 65 (NUMA domain 4), from core 0 (NUMA domain 0), would have a distance over three times longer.
Binding and distribution in Slurm¶
MPI exposes some options for pinning and distributing processes, but this section focuses on the options available for Slurm.
CPU Binding¶
Now, to use the architecture described above optimally, some Linux characteristics have to be taken into account. One of the properties is that threads can change which core they run on halfway through the run. This is done by the Linux scheduler for load balancing, but it produces a problem if we consider the NUMA domain arrangements described previously. If a thread runs on core 0 for half of the job, and then switches to core 65 for the rest of the run, then it would still be accessing the memory in NUMA domain 0. This means that the memory access times for the rest of the runs would be 3 times slower. This is where binding comes into play.
Binding, as the name hints, allows us to set limits as to how the scheduler manages these threads. Slurm, for example, allows us to bind processes using the --cpu-bind=<option> in the following ways.
threads- binds to logical threadscores- binds to coressockets- binds to socketsmap_cpu:<list>- specify a CPU ID binding for each task where<list>is<cpuid1>,<cpuid2>,...<cpuidN>mask_cpu:<list>- specify a CPU ID binding mask for each task where<list>is<mask1>,<mask2>,...<maskN>
Using the command taskset(lets us see CPU affinity/ which CPUs a task has access to), let's see the effects of these different options.
Here we bind the tasks to threads and we can see that each of the process reports just 1 logical core.
$ salloc -p main -N 1 --exclusive
$ export SLURM_CPU_BIND=threads # You can use either this or the srun flag --cpu-bind=threads
$ srun -n 4 --cpus-per-task 32 bash -c \
' echo -n "task $SLURM_PROCID (node $SLURM_NODEID): "; taskset -cp $$' | sort
task 0 (node 0): pid 206910`s current affinity list: 0-31
task 1 (node 0): pid 206911`s current affinity list: 32-63
task 2 (node 0): pid 206912`s current affinity list: 64-95
task 3 (node 0): pid 206913`s current affinity list: 96-127
Here we bind the tasks to cores and we can see that each of the process reports a core and it's corresponding SMT part.
$ salloc -p main -N 1 --exclusive
$ export SLURM_CPU_BIND=sockets
$ srun -n 4 --cpus-per-task 32 bash -c \
' echo -n "task $SLURM_PROCID (node $SLURM_NODEID): "; taskset -cp $$' | sort
task 0 (node 0): pid 207609`s current affinity list: 0-31,128-159
task 1 (node 0): pid 207610`s current affinity list: 32-63,160-191
task 2 (node 0): pid 207611`s current affinity list: 64-95,192-223
task 3 (node 0): pid 207612`s current affinity list: 96-127,224-255
Here we bind the tasks to sockets and thus the first 2 tasks have the affinity of 0-63 (first socket) and the other 2 have the affinity of 64-127 (second socket).
$ salloc -p main -N 1 --exclusive
$ export SLURM_CPU_BIND=sockets
$ srun -n 4 --cpus-per-task 32 bash -c \
' echo -n "task $SLURM_PROCID (node $SLURM_NODEID): "; taskset -cp $$' | sort
task 0 (node 0): pid 208307`s current affinity list: 0-63,128-191
task 1 (node 0): pid 208308`s current affinity list: 0-63,128-191
task 2 (node 0): pid 208309`s current affinity list: 64-127,192-255
task 3 (node 0): pid 208310`s current affinity list: 64-127,192-255
It is possible to specify exactly where each task will run by giving Slurm a list of CPU-IDs to bind to. Sometimes it is beneficial to do this if you have a job that has a memory bandwidth bottleneck, in a way that spreads out the MPI ranks across all compute core complexes (CCDs, L3 cache). Typically, this is done to get more effective memory capacity and memory bandwidth per MPI rank and increase cache capacity available to each rank. In the case of Aretmis nodes, which have AMD EPYC 7763 CPUs, you could do this by specifying a map like export SLURM_CPU_BIND="map_cpu:0,8,16,24,32,40,48,56,64,72,80,88,96,104,112,120", so every eighth CPU -> 1 CPU per CCD.
In this example we will run 4 tasks and tell the Slurm scheduler exactly that we want to run those 4 tasks on CPUs indexed 0,32,64 and 96.
$ salloc -p main -N 1 --exclusive
$ export SLURM_CPU_BIND="map_cpu:0,32,64,96"
$ srun -n 4 --cpus-per-task 32 bash -c \
' echo -n "task $SLURM_PROCID (node $SLURM_NODEID): "; taskset -cp $$' | sort
task 0 (node 0): pid 208982`s current affinity list: 0
task 1 (node 0): pid 208983`s current affinity list: 32
task 2 (node 0): pid 208984`s current affinity list: 64
task 3 (node 0): pid 208985`s current affinity list: 96
This section is from the LUMI documentation. For hybrid MPI+OpenMP application multiple core need to be assigned to each of the tasks. These can be achieved by setting a CPU mask, --cpu-bind=cpu_mask:<task1_mask,task2_mask,...>, where the task masks are hexadecimal values. For example, with 16 tasks per node and 4 cores (threads) per task, one every 2 cores assigned to the task. In this scenario, the base mask will be 0x55 in hexadecimal which is 0b01010101 in binary. Then, to binding masks for the tasks will be
- First task
0x55: cores 0, 2, 4 and 6 - Second task
0x5500: cores 8, 10, 12 and 14 - Third task
0x550000: cores 16 18 20 and 22 - ...
So the CPU mask will be 0x55,0x5500,0x550000,.... Setting the CPU mask can be tedious, below is an example script that computes and set the CPU mask based on the values of SLURM_NTASKS_PER_NODE and OMP_NUM_THREADS. We will set it to run the same executable as before and look at the output
#!/bin/bash
#SBATCH --nodes=1
#SBATCH --ntasks-per-node=16
#SBATCH --cpus-per-task=8
#SBATCH --exclusive
#SBATCH --partition=main
#SBATCH --time=00:10:00
#SBATCH --time=00
export OMP_NUM_THREADS=4
export OMP_PROC_BIND=true
export OMP_PLACES=cores
cpus_per_task=$((SLURM_CPUS_ON_NODE / SLURM_NTASKS_PER_NODE))
threads_spacing=$((cpus_per_task / OMP_NUM_THREADS))
base_mask=0x0
for i in $(seq 0 ${threads_spacing} $((cpus_per_task-1)))
do
base_mask=$((base_mask | (0x1 << i)))
done
declare -a cpu_masks=()
for i in $(seq 0 ${cpus_per_task} 127)
do
mask_format="%x%$((16 * (i/64)))s"
task_mask=$(printf ${mask_format} $((base_mask << i)) | tr " " "0")
cpu_masks=(${cpu_masks[@]} ${task_mask})
done
export SLURM_CPU_BIND=$(IFS=, ; echo "mask_cpu:${cpu_masks[*]}")
echo $SLURM_CPU_BIND
srun bash -c ' echo -n "task $SLURM_PROCID (node $SLURM_NODEID): "; taskset -cp $$' | sort
We see that the outputs of $SLURM_CPU_BIND and taskset are the following.
mask_cpu:55,5500,550000,55000000,5500000000,550000000000,55000000000000,5500000000000000,550000000000000000,55000000000000000000,5500000000000000000000,550000000000000000000000,55000000000000000000000000,5500000000000000000000000000,550000000000000000000000000000,55000000000000000000000000000000
task 0 (node 0): pid 229380's current affinity list: 0,2,4,6
task 10 (node 0): pid 229390's current affinity list: 80,82,84,86
task 11 (node 0): pid 229391's current affinity list: 88,90,92,94
task 12 (node 0): pid 229392's current affinity list: 96,98,100,102
task 13 (node 0): pid 229393's current affinity list: 104,106,108,110
task 14 (node 0): pid 229394's current affinity list: 112,114,116,118
task 15 (node 0): pid 229395's current affinity list: 120,122,124,126
task 1 (node 0): pid 229381's current affinity list: 8,10,12,14
task 2 (node 0): pid 229382's current affinity list: 16,18,20,22
task 3 (node 0): pid 229383's current affinity list: 24,26,28,30
task 4 (node 0): pid 229384's current affinity list: 32,34,36,38
task 5 (node 0): pid 229385's current affinity list: 40,42,44,46
task 6 (node 0): pid 229386's current affinity list: 48,50,52,54
task 7 (node 0): pid 229387's current affinity list: 56,58,60,62
task 8 (node 0): pid 229388's current affinity list: 64,66,68,70
task 9 (node 0): pid 229389's current affinity list: 72,74,76,78