Sensitive data analysis platform¶
The Sensitive data analysis platform or SAPU is an environment provided by the University of Tartu High-Performance Computing Center, where data owners from within and without UT can make datasets available for analysts and programmers to work on in a secure, controlled and auditable way. The environment reduces the risk of unauthorized copy, transfer, or retrieval of sensitive data from the working environment, providing a higher class of security than that of a standard high-performance cluster.
Overview¶
SAPU workstations are an isolated environment where:
- The workstation has no access to the outside world.
- Complete network isolation based on firewall rules.
- Analysts access their workstations only via a remote desktop gateway.
- Remote desktop sessions are recorded.
- Data ingress and egress is handled by a data gateway.
- S3-based: all actions are atomic and easily auditable.
- Versioned: every version of every file to enter and exit the workstation can be retrieved on demand.
- Data egress requires approval by Data Owner or Data Steward.
- The monitoring layer records all actions taken.
- Live audit data is available to Data Owners and Stewards
People working in SAPU are divided into the following roles:
| Role | Permissions | Notes |
|---|---|---|
| Cloud Operators | Admin privileges everywhere. | The UTHPC center fills this role by taking care of the security, monitoring and operational tasks, making sure the machines work. |
| Data Owners | Access to workstation, data gateway, monitoring. | This role consists of people who own the data. They provide analyzable data, review data submitted for egress. |
| Data Stewards | Access to workstation, data gateway, monitoring. | Technical representatives of the data owners - responsible for technical tasks, helping cloud operators and analysts. |
| Data Analysts | Access to workstation, data released from data gateway | People who work with the data. |
Requesting a project¶
Any and all requests pertaining to setup or reconfiguration of anything in the SAPU environment need to be submitted by a Data Owner or Steward.
Requests should be submitted to support@hpc.ut.ee with a list of requirements.
The list of requirements should contain the following
- The name of the project. This will also become the workstation's name.
- Duration of the project. Data in the data gateway and all logs will persist for this duration, unless requested otherwise.
- List of users, divided into their roles.
- Contact information for data owners, custodians and analysts.
- Necessary CPU, memory and disk resources.
- List of necessary software to be set up beforehand.
Afterwards, Cloud Operators create a virtual workstation with the specified resources and software. Then, Data Owners and/or Stewards move the necessary data into the data gateway, after which Analysts get access to the workstation.
Note
The workstation will continue to incur costs for the duration of the project. During periods of inactivity these costs can be reduced by requesting the workstation be shelved (only storage - both data and logs - will be billed) or archived (same as shelved, but at a greatly reduced price).
Operations¶
This paragraph explains and walks through some common tasks related to SAPU.
Account handover¶
Users receive their credentials through a previously agreed-upon method. Choice of method depends on the user's affiliation with UT and/or tools already at the user's disposal. Some possible methods include:
| Method | Subject | Notes |
|---|---|---|
| UTHPC Vault . | People affiliated with the University of Tartu. | |
| Encrypted .asice envelope | Anyone with an Estonian ID-card | Can also be used by people with residence permits, and e-residents |
| GPG-encrypted envelope | Anyone with GPG-keys | Requires some technical knowledge |
| Two separate channels | Anyone | User receives an encrypted file through one channel, and the encryption key through another |
Logging in¶
After receiving the credentials, you can log in through the Virtual Desktop gateway .
Upon first login, you will be required to:
- Change your password
- Configure MFA
After logging in, if you only have access to one workstation, you'll be forwarded there immediately. Currently, you will have to re-authenticate once you reach the workstation. If you have access to several workstations, they will be visible under the ’ALL CONNECTIONS’ tab. Clicking on a connection will initiate a remote desktop session with the respective workstation.
Accessing Guacamole settings¶
While on the Guacamole landing page, a limited number of settings (relating to appearance, display language and input methods) can be configured via the Preferences menu, by clicking on your username on the top-right, choosing settings from the drop-down menu, and navigating to the 'Preferences` tab. Once in a remote desktop session, a similar menu will open with the keyboard combination Ctrl+Alt+Shift. The one-way clipboard can also be accessed here. Additionally, if you have access to more that one workstation, you can hop between connections to those workstations via a drop-down menu at the top of the page. It's used to access other hosts, settings, or the clipboard.
Changing your password¶
Passwords can be changed in the SAPU identity server when inside University of Tartu internal network - either by wired connection, by utilizing the VPN, or EduRoam WIFI.
If you do not have access to any of those methods, it is possible to change your password by opening the terminal app (called Tilix) in your remote desktop session and using the passwd command. Alternatively, you can request a password reset by e-mail from support@hpc.ut.ee
Secure Data Gateway¶
The SAPU Secure Data Gateway can be accessed at console.object.hpc.ut.ee , by clicking on "Other Authentication Methods" and selecting "SAPU" from the drop-down menu. Once logged in, a list of buckets in the format of <project_name>.sapu.hpc.ut.ee becomes visible. These buckets represent the various workstations the user has access to, and are central for data ingress and egress into/from the environment.
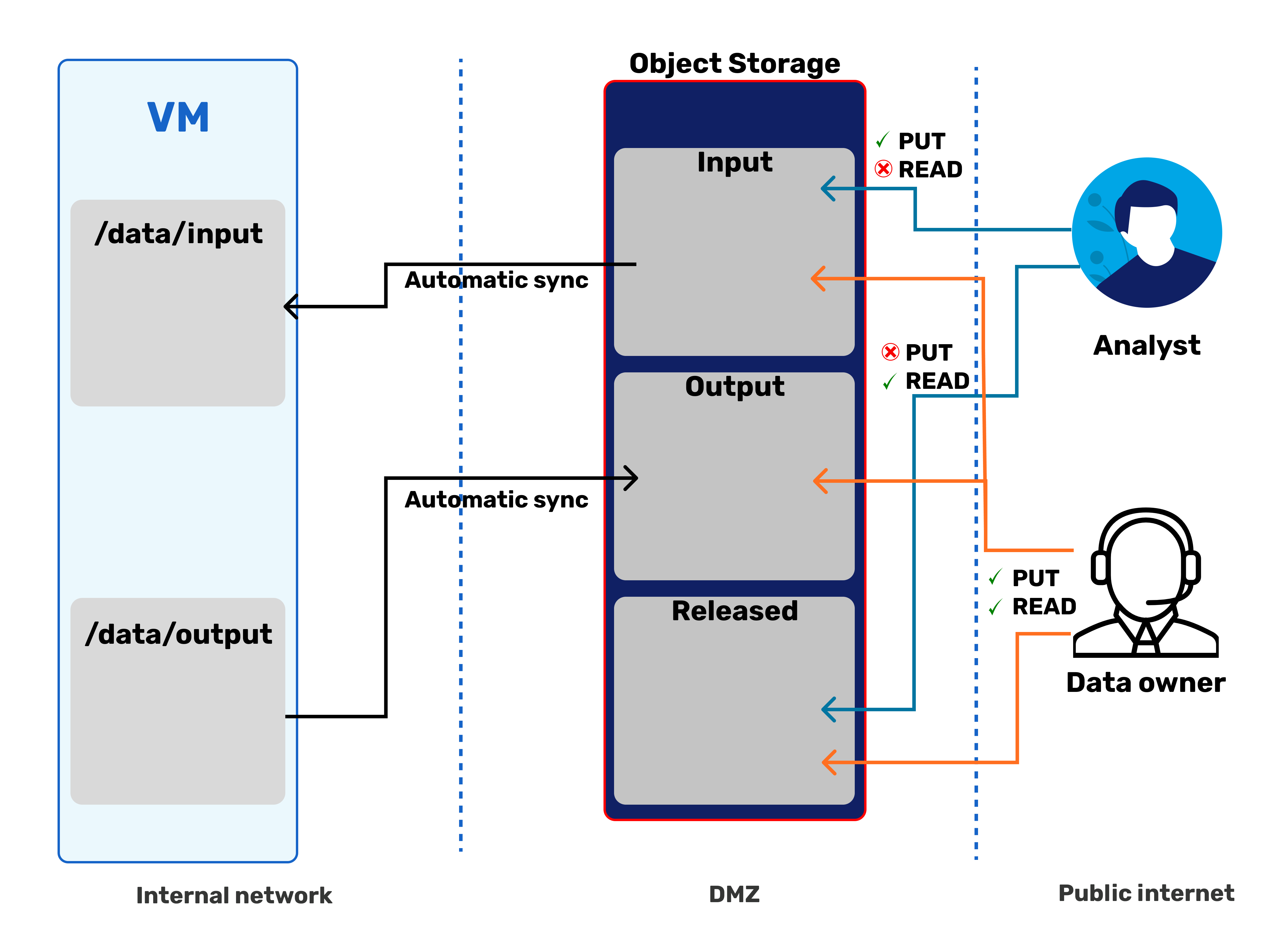
Browsing inside reveals three folders - input, output, and released.
<project>.sapu.hpc.ut.ee/
├── input #(1)
├── output #(2)
└── released #(3)
- Data analysts can read from and write into this folder; the workstation synchronizes this folder to
/storage/data/input/. - Data analysts can't read nor write this folder; the workstation synchronizes this folder from
/storage/data/output/. - Data analysts can only read from this folder; Data Owners/Stewards manually place data here.
-
- The
inputfolder is for moving files into SAPU from the outside world. - The
outputfolder is for requesting release of files from SAPU into the outside world. Data Owners and/or Stewards review files placed here and, if deemed safe for release, move them toreleased. - The
releasedfolder is from where a Data Analyst can download the approved output files.
- The
Moving data into SAPU¶
Data can be moved into a SAPU workstation by using the workstation's input folder in the data gateway. Files can be uploaded into the gateway either via the web-console or any S3-compliant utility (internally, the workstations use rclone, for example). Depending on file size and bucket size, sync between the gateway and the workstation can take up to 5 minutes.
Submitting data to be released¶
Moving data out of SAPU has two phases. First, the Data Analyst moves the file into the output/ folder within their workstation (usually located at /storage/data/output/). This file will then be automatically synchronized to the output folder in the data gateway.
After moving the file, the Data Analyst notifies either the Data Owners or Stewards, who then inspect the files. If the files meet the data protection, security, and policy standards, the Data Owner or Steward moves the file into the released folder in the data gateway, from which the Data Analyst will then be able to download it.
Reviewing and releasing data¶
Releasing data is essentially just moving a file from the output folder in the data gateway to the released folder. Unfortunately, the data gateway's web console dos not implement a move or copy command. This means that the file will need to be downloaded from output and subsequently uploaded to released. If reviewing data on a local computer, this will luckily already be part of your workflow.
Data Owners and Stewards additionally have the option to use the SAPU workstation itself as a secure place to review data submitted to be released. In that case you will need to use the workstation's rclone to interact with the data gateway and manage the release, which requires some one-time setup:
- Log in to the data gateway's web console and create an access key for your account.
- When logged in, click on "Access Keys" -> "Create access key" -> edit the "Access Key" and "Secret Key" fields according to preference -> "Create"
- From within your SAPU workstation, open a terminal and run the following to create a configuration directory for
rcloneand move into that directory:mkdir -p ~/.config/rclone && cd ~/.config/rclone/ - Next, create a file named
rclone.confand open it for editingnano rclone.conf - Fill the configuration file out as follows
[data-gw] type = s3 provider = Minio access_key_id = YOUR-ACCESS-KEY-HERE secret_access_key = YOUR-SECRET-KEY-HERE endpoint = https://object.hpc.ut.ee - To save and exit, press in sequence Ctrl+X followed by Y and then Enter
- Next, tighten the permissions of your configuration file.
chmod 600 rclone.conf - To verify that the configuration is valid, try listing the files in your data gateway bucket's output folder
rclone ls data-gw:<name-of-your-workstation>.sapu.hpc.ut.ee/output/
To verify candidate data for release, we recommend copying the submitted file from /storage/data/output (or equivalent path in the data gateway) to your home folder and then - provided the data survives scrutiny - moving that file to the data gateway's released folder. The command for the latter operation is as follows
rclone copy path/to/file/in/workstation data-gw:<name-of-your-workstation>.sapu.hpc.ut.ee/released/